

到目前为止,我们还没有谈论过太多的一件事混合建模博客系列在为我们的计算添加更多资源时,我们可以期望得到什么。今天,我们考虑了一些理论研究,这些研究解释了并行计算中的局限性。我们还将向您展示如何使用comsol软件的188金宝搏优惠批处理选项,这是一个内置的选项,令人尴尬的平行功能在达到这些限制时,要提高性能。
Amdahl和Gustafson-Barsis的法律
我们之前已经提到了如何通过添加计算单元的加速取决于算法(在本文中,我们将使用该术语过程,但添加的计算单元也可以是线程)。一个严格串行算法,就像计算元素斐波那契系列,从附加的过程中根本受益,而平行算法,就像添加向量一样,可以使用与矢量中的元素一样多的处理器。现实世界中的大多数算法都在这两者之间。
为了分析算法的最大速度,我们将假设它由一小部分可行的代码和一小部分严格的串行代码组成。让我们调用并行代码的分数\ varphi, 在哪里\ varphi是(和包括)0和1之间的数字。这自动意味着我们的算法具有等于(1- \ varphi)。
考虑到计算时间,t(p), 为了p主动过程,从案例开始p = 1,我们可以使用表示形式t(1)= t(1)\ cdot(\ varphi +(1- \ varphi))。运行时p过程,代码的串行分数不受影响,但是将计算完美平行的代码p时间更快。因此,计算时间p过程是t(p)= t(1)\ cdot(\ varphi / p +(1 - \ varphi)),加速是s(p):= = t(1)/t(p)= 1/(\ varphi/p+(1- \ varphi))。
Amdahl的定律
这种表达是Amdahl的定律。绘图s(p)对于不同的值\ varphi和p,我们现在在下图中看到一些有趣的东西。
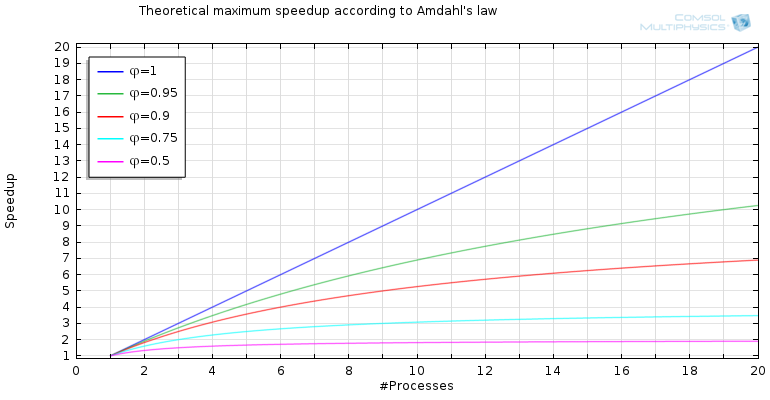
增加可行代码不同分数的过程数量的加速。
对于100%并行的代码,天空是极限。但是,我们发现\ varphi <1,渐近极限或理论最大速度是s_ {max}(\ varphi):= \ lim_ {p \ to \ infty} s(p)= 1/(1- \ varphi)。
对于95%的并行代码,我们发现s_ {max}(0.95)= 20- 即使我们有无限数量的流程,最大速度也是二十倍。此外,我们有s_ {max}(0.9)= 10,,,,s_ {max}(0.75)= 4, 和s_ {max}(0.5)= 2。当减少并行代码的分数时,理论最大加速会迅速减少。
但是不要放弃暂时回家!
Gustafson-Barsis的法律
Amdahl的法律有一件事不是考虑一下,这就是事实,当我们购买更快,更大的计算机以运行更多流程时,我们通常不想从昨天快速计算我们的小型型号。取而代之的是,我们想计算新的,更大(和凉爽的)型号。那就是Gustafson-Barsis的法律全部。这是基于以下假设:我们要计算的问题的大小随可用过程的数量线性增加。
Amdahl的定律假定问题的大小是固定的。在添加新处理器时,他们正在处理最初由较少数量流程处理的问题的一部分。通过添加越来越多的流程,您不会利用添加过程的全部能力作为最终能够在达到下限的能力的大小。然而,通过假设问题的大小随添加过程的数量增加,您将所有过程都将所有进程用于假定的级别,并且执行的计算的速度仍然没有结合。
描述这种现象的方程式是s(p)= \ phi \ cdot p-(1- \ phi),这给我们带来了更加乐观的结果缩放速度(就像生产力一样),如下图所示:
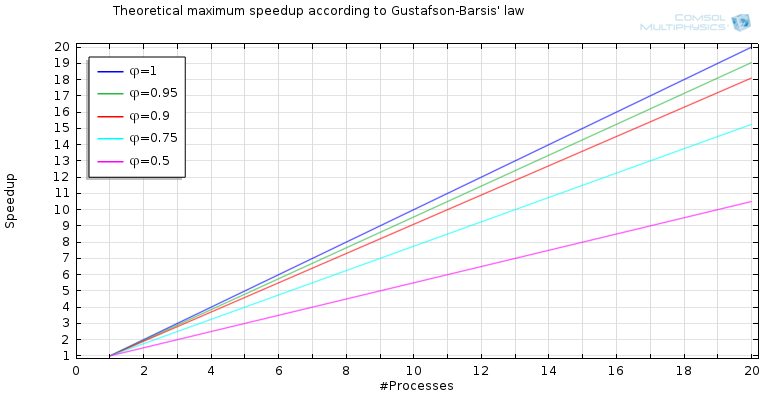
当考虑到工作规模通常随着可用过程的数量而增加时,我们的预测更加乐观。
沟通成本
Gustafson-Barsis的定律意味着我们只限制了我们可以通过添加流程的资源来计算的问题的规模。然而,还有其他因素会影响加速。到目前为止,我们试图强调的事情这个博客系列沟通是昂贵的。但是我们还没有谈论它的昂贵,所以让我们看一些示例。
让我们考虑一个由并行处理中所需的通信和同步主导的开销,并将其建模为添加到计算时间的时间。这意味着当我们增加流程数量时,通信量增加,并且这种增加将由功能建模哦(p)= c \ cdot f(p), 在哪里C是一个常数f(p)是一些功能。因此,我们可以通过:s(p)_ {oh} = 1/(\ varphi/p+(1- \ varphi)+c \ cdot f(p))。
下图显示了并行代码的分数为95%的情况,并且可以看到越来越多的过程的加速度,用于不同功能f(p), 假设C= 0.005(此常数在不同的问题和平台之间会有所不同)。在没有开销的情况下,结果是Amdahl定律所预测的,但是当我们开始添加开销时,我们会发现正在发生某些事情。
对于线性增加的开销,我们发现,在通信开始抵消更多流程添加的增加计算功率之前,加速度的值未达到五个大于五个的值。对于二次函数,f(p),结果甚至更糟,您可能会从我们之前的博客文章中记得分布式内存计算在全能的沟通情况下,沟通的增加是二次的。
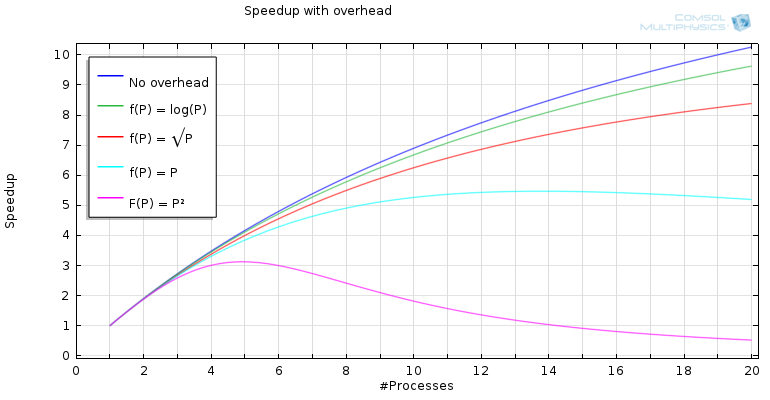
加上添加开销的加速。常数c被选择为0.005。
由于这种现象,我们不能指望在添加越来越多的过程时,在集群上加速群集。沟通量的增加速度将比附加流程中的任何收益更快。但是,在这种情况下,我们只考虑了固定的问题大小,并且随着我们增加问题的规模,通过通信引入的“放缓”效果将不太相关。
comsol多物理学中的批量扫描188金宝搏优惠
现在让我们离开理论方面,学习如何利用COMSOL多物理学中的批处理扫描功能。188金宝搏优惠作为我们的示例模型,我们将使用无电灯,该灯可在模型画廊。该模型在约80,000度的自由度下很小,但解决方案需要大约130个时间步骤。为了使此瞬态模型参数,我们将计算几个灯功率值的模型,即50 W,60 W,70 W和80W。
在我的工作站上,配备了Intel®Xeon®E5-2643Quad Core处理器和16 GB RAM的Fujitsu®Celsius®收到以下计算时间:
| 核心数 | 每个参数计算时间 | 计算扫荡的时间 |
|---|---|---|
| 1 | 30分钟 | 120分钟 |
| 2 | 21分钟 | 82分钟 |
| 3 | 17分钟 | 68分钟 |
| 4 | 18分钟 | 72分钟 |
这里的加速远非完美 - 三个核心仅1.7架,甚至在四个内核中减少了。这是由于事实是,这是一个小型模型,每个时间步骤内每个线程的自由度数量较低。
现在,我们将使用批处理扫描功能以另一种方式并行化此问题:我们将从数据并行性至任务并行性。我们将为每个参数值创建一个批处理作业,并查看这对我们的计算时间有何影响。为此,我们首先激活“高级研究选项”,然后右键单击“研究1”并选择“批次扫描”,如下所示:
如何在模型中激活批处理,包括参数值,并指定同时作业的数量。
下图指示我们可以通过控制并行化来获得生产率或“加速”。当使用四个内核运行一个批处理作业时,我们从上面获得结果:72分钟。当将配置同时更改为两个批处理作业时,每个作业都使用两个内核,我们可以在48分钟内计算所有参数。最后,当同时计算四个批次作业时,每个处理器都使用一个处理器,总计算时间为34分钟。这给出了2.5次和3.5次的加速度 - 与仅使用纯共享内存并行化相比,要好得多。
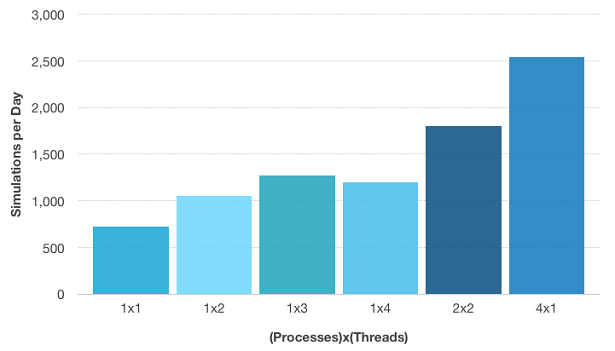
无电灯模型每天的仿真。“ 4×1”是指使用每个核心同时运行四个批次作业。
结论混合建模系列
始终博客系列,我们已经了解了共享,分布和混合记忆计算以及它们的弱点和优势以及并行计算的巨大潜力。我们还了解到,计算机上没有免费的午餐。我们不能仅仅添加流程,并希望为所有类型的问题提供完美的加速。
取而代之的是,我们需要选择并行解决问题的最佳方法,以从硬件中获得最大的性能增益,就像我们必须选择正确的求解器以在解决数值问题时获得最佳的解决方案时间一样。
选择正确的并行配置并不总是那么容易,并且很难事先知道如何“杂交”并行计算。但是,与许多其他情况一样,经验来自玩耍和测试,并且使用Comsol Multiphysics,您有可能这样做。188金宝搏优惠使用不同的配置和不同的型号尝试一下,您很快就会知道如何设置软件,以便从硬件中获得最佳性能。
富士通是美国和其他国家的富士通有限公司的注册商标。Celsius是美国和其他国家的富士通技术解决方案的注册商标。英特尔和Xeon是美国和/或其他国家的英特尔公司的商标。


评论(2)
Amr al Abed
2014年8月13日我注意到该模型是在工作站上解决的。如果要在集群上解决此模型,是否仍建议使用批处理?还是群集扫荡会更加优势?如果是这样,群集与批处理扫描有什么好处?
PärPerssonMattsson
2014年8月15日嗨,阿姆尔,
如果要在集群上解决此模型,则需要使用群集清扫或群集计算功能。批处理扫描和集群扫描之间的区别在于,批处理仅在您打开模型的计算机上仅在本地运行,并且可以将群集扫描配置为使用工作调度程序或在远程计算机上运行(即使在云中!)。